✍️ Contextual Conversations – remembers your chat history across messages
🤖 Model Switching – change models (e.g. GPT-3.5 ↔ GPT-4) on the fly without losing context
🖼️ Image Generation – describe what you want and get visuals via DALL·E
📄 PDF Q&A – upload a PDF and ask natural questions about its contents
🔐 Secure Auth – session-based access with password + token + CSRF protection
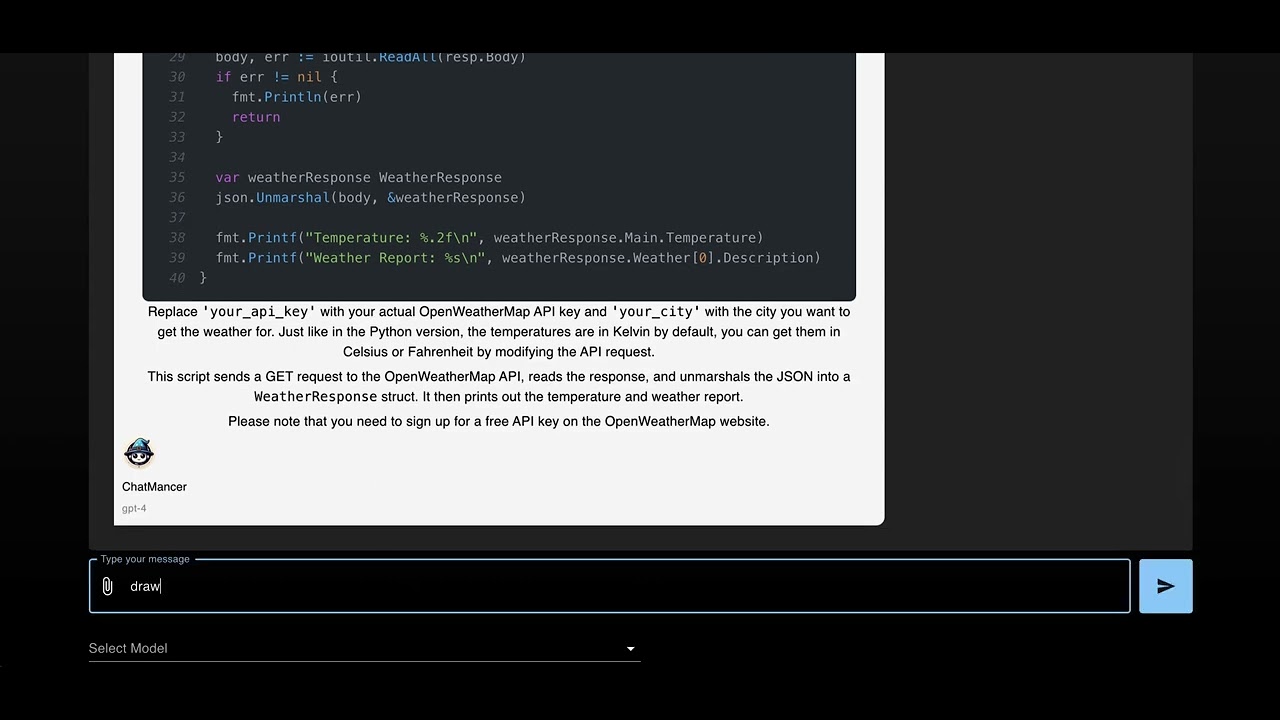
🧠 Code Display – beautifully rendered code with syntax highlighting and language labels
ChatMancer is a full-stack app powered by large language models (LLMs) that delivers an advanced, ChatGPT-like experience with added flexibility, control, and lower cost potential. Built on OpenAI's API, it supports contextual conversations, image generation, and document analysis — with full model-switching support.
- Custom memory system preserves message history across requests using session IDs.
- Tracks user/AI messages, model used, and content type (text or image).
- Supports future features like analytics, , or persistent logging.
- Easily switch between models (e.g., GPT-4, Claude) at any time.
- Session memory remains intact regardless of which model is used.
- Chat history is tracked separately from the LLM logic for full flexibility.
- Users can generate images using natural prompts like "draw a dragon in a coffee cup" — no command prefix needed.
- Powered by DALL·E.
- Image messages are stored with
content_type: "image"for structured frontend rendering.
- Upload a PDF and ask questions about it directly.
- RAG (retrieval augmented generation) pipeline extracts and answers using the document.
- Automatically detects relevant context without requiring a command prefix.
- Uses custom
invoke_with_metadata()to manage LLM execution, memory storage, and message tagging in one place. - Code blocks are rendered with fenced Markdown (```lang) and copy buttons for readability.
- Flexible memory architecture supports per-message metadata, like model and content type.
Text file upload and QA support (RAG)- Add support for pulling content from URLs
- GPT Vision / image Q&A support
Persistent model selection with historical trackingResponse .
This project uses OpenAI's APIs, which are not free. Costs depend on:
- Number of requests
- Models used (e.g., GPT-4 is more expensive than GPT-3.5)
- Image generation and embeddings
Most casual users will spend <$10/month, but you can set limits via your OpenAI billing dasard (e.g., $20 cap).
In your .env file under /api:
Your OpenAI API key. Required for GPT and DALL-E access.
Password protection for the app interface (basic access control). Passwords need to be encrypted using /api/lib/pass.py
git clone https://.com/alexbenko/ChatMancer.git
cd ChatMancer- Add
.envto/apiwith required variables. - Build Docker image:
docker build -t chatmancer .- Run it:
docker run -p 8000:8000 chatmancer- Open the printed URL, enter the password, and chat away.
git clone https://.com/alexbenko/ChatMancer.git
cd ChatMancer- Install Python server deps:
pip install -r requirements.txt- Add your
.envfile in/api:
OPENAI_API_KEY=your_key
PASSWORD=your_password- Start backend:
cd api
python main.py- Start frontend:
cd ../web
npm install
npm run dev- Visit the printed URL and authenticate.
- Vite — Lightning-fast frontend tooling
- React — UI library
- TypeScript — Static typing
- Python 3.11 — Backend language
- FastAPI — Async web framework
- LangChain — LLM orchestration and memory
- OpenAI API — GPT + DALL-E access
Open to PRs, ideas, and feedback!
see LICENSE for full details.